





Sentetik Veri Türleri ve Oluşturma Yöntemlerini anlatmaya geçmeden önce sizlere sentetik veri hakkında biraz bilgi vermek istiyorum. Sentetik veriden bahsederken günlük hayatımızdan örnek verebiliriz. Günlük hayatımızda bazen işimizden dolayı ya da insanlarla girmiş olduğumuz etkileşim nedeniyle bazı veriler elde ederiz. Bu topladığımız veriler bir bilgisayar algoritması tarafından tamamen yeni ve yapay veri noktalarına dayanarak üretildiğinde ise Sentetik Veriler oluşur.
Sentetik Veriler, üretim verilerinin istatistiksel özelliklerine benzer bir şekilde çalıştıkları için farklı bölümlerde kullanılmaktadır. Yeni ürün ve hizmetlerin testini gerçekleştirmek ,modellerin doğruluğunu test etmek veya performanslarını değerlendirmek için kullanılmaktadır. Günümüzde sentetik veriler ile ilgili bir araştırma yaptığınızda farklı türde yapılandırılmış ve yapılandırılmamış sentetik verileri göreceksiniz.
Sentetik veriler, çeşitli uygulamalar için en önemli kaynak haline geldi. Çünkü Sentetik Veriler orijinal verilerle neredeyse tamamen benzer, bir algoritma sayesinde oluşturulmuş yapay verilerdir.
İşini gerçekleştirirken hassas veya kişisel verilere önem veren ve bu verilere güvenen çoğu sanayi sentetik verileri kullanarak güvenlik ve gizlilik gibi endişelerini ortadan kaldırmış oldular. Bunun yanında yukarıda bahsettiğimiz gibi Sentetik Veriler, üretim verilerinin istatistiksel özelliklerine benzer bir şekilde çalıştıkları için yeni ürün ve hizmetlerin testini gerçekleştirir modellerin doğruluğunu test eder ve performanslarını değerlendirir bu yüzden endüstriler işlerini gerçekleştirirken Sentetik Veriden yararlanırlar.
Farklı sentetik veri türleri
Sentetik Verilerin kullanılmaya başlanması ve bu kullanımın yaygınlaşmasından dolayı Sentetik Veriler kendi içinde yeni türlere ayrılmıştır. Bu yeni türlerin oluşmasının en belirgin sebebi sentetik verinin yeni endüstri kollarında kullanılıyor olmasıdır. Her endüstri kendi işine yaracak ve işini kolaylaştıracak yeni bir Sentetik Veri türü oluşturarak günümüze şu türleri getirmişlerdir.
Metin
Sentetik verilerden en çok bilineni ve genellikle diğer türlere göre daha yoğun bir şekilde kullanılan Sentetik veri türü metindir. Sentetik veriler bir algoritma sayesinde oluşturulmuş yapay metinler olabilir. Günümüzde, makine çeşitleri, makine öğrenme ve bir makineyi eğitebilmek için oldukça yüksek verimli bir Sentetik Veri türüdür. Bu Sentetik Veri türü doğal dil üretme sistemlerinde yoğun olarak kullanıldığı için şu anda büyük bir şirket olan Amazon’un yapmış olduğu Alexa Al ekibi doğal dil işleme alanında sentetik verileri kullanıyor.
MEDYA
Sentetik veriler metinler dışında video, resim veya ses formatında olabilir. Sentetik veriler video, görüntü ve ses olduklarında gerçek hayattaki orijinal ortamlarla çok benzerlik gösterdikleri için orijinal ortamların yerlerine geçerek kullanılmasına olanak sağlamıştır. Örnek verecek olursak bir yüz tanıma sistemi veri tabanını genişletmek istediğimizde bu medya Sentetik Türü işimizi çok büyük ölçüde kolaylaştırır.
Uzun süredir gerçekçi sürüş veri kümeleri oluşturmak için çalışan Waymo ekibi Sentetik Verilerden yararlanmaktadır. Alphabet’in yan kuruluşu olan Waymo, sürücüsüz araç sistemlerini eğitebilmek , gözlemler elde edebilmek için uzun süreçler ve büyük miktarda paralar harcamak yerine Sentetik Verileri kullanıp işlerini büyük ölçüde kolaylaştırıyor.
Tablo Verileri
Tablo şeklinde olan sentetik veriler, gerçek hayatta tablo sistemiyle depolanan verileri, algoritma sayesinde yapay olarak oluşturulan ve depolanan verileri ifade eder. Tablo verilerini bir örnek üzerinden anlatmak gerekirse, tablo sistemiyle bir hasta veri tabanı oluşturduğumuz var sayalım. Bu veri tabanındaki veriler hastanın tahlillerini ya da finansal günlüklerine kadar her şey olabilir. Sentetik veriler her türlü davranış analizi , işlemsel analiz ve varsayıma dayalı analizin yerine geçip aynı işlevi görebilirler.
Sigortacılık alanında faaliyet gösteren İsviçreli bir şirket olan La Mobiliere, kayıp tahmin modellerini eğitebilmek için Sentetik Verileri kullandı. La Mobiliere ‘ in veri bilim ekibi makine öğrenim modellerini sentetik verilerle eğiterek kullanamayacakları kadar hassas olan gerçek hayattaki müşteri verilenden tablo şeklindeki sentetik verileri modelledi.
Sentetik Veri Oluşturma Yöntemleri
Sentetik verilerin üretilmesi, aynı oranla yeni bir veri kümesi oluşturabilmek için orijinal veri kümesinin ortak olasılık oranını öğrenmekten geçmektedir.
Kuramda, kolay bir tablo ve çok az miktarda sütun ile birlikte kolay bir model eşleme dağılımı, sentetik verileri oluşturmanın çabuk ve zor olmayan bir yolu olabilir. Bununla beraber, veri kümesi ne kadar karmaşık ve ne kadar uzunsa verileri eşlemek o kadar zor olur.
Ne kadar çok sütun ve ne kadar çok tablo eklerseniz o kadar fazla olasılık olacağı için dağılım doğru bir şekilde öğrenmede sıkıntı yaşarsınız. Bu sebeple böyle verileri çözebilmek için daha gelişmiş bir modele ihtiyacımız var.
Son yıllarda makine öğreniminin gelişmesi ile birlikte önümüze çeşitli veri türleri sunuldu. Bunlardan yaygın olarak kullanılan iki tanesi şunlardır:
Varyasyonel Otomatik Kodlayıcılar
Veri Akış Erişimi (VAE) ‘ler , denetlenmeyen eğitim alanından ve otomatik kodlayıcı ailesinden gelirler. Üretken modeller oldukları için orijinal verilerin temeldeki dağılımlarını öğrenmek ve karmaşık modeller oluşturmak için çok önemli ve etkilidirler.
VAE’ler iki adımda çalışırlar. Öncelikle bir kodlayıcı ağı, orijinal dağıtımı gizli bir dağıtıma dönüştürür. Bir dekoder ağı sonrasında bu gizlenen dağıtımı orijinal haline dönüştürür. Kodlanan kodu deşifre edilmiş bu ikili dönüşüm, ilk başta çok karışık ve zahmetli gözükebilir fakat ölçülebilir yeniden yapılandırma hatasını formüle dönüştürebilmek için bu işlem gereklidir. VAE eğitimin asıl amacı bu işlemde gerçekleşebilecek hataları en aza indirmektir.
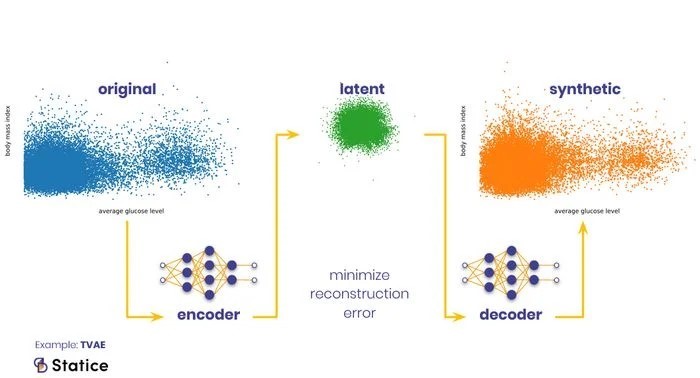
VAE’ler dönüşüm problemini çözebilmek için basit yoldur. Uygulaması ve öğretilmesi diğer yollara göre daha kolaydır. Ancak zayıf noktaları yok diyemeyiz, orijinal verileriniz heterojen hale geldikçe, tüm veri elemanlarında iyi çalışabilen bir yeniden yapılandırma hatası formüle edebilmek daha zor hale gelir.
Üretken Çekişmeli Ağlar
GAN’lar da VAE’ler gibi denetlenmeyen eğitim alanlarından ve üretici aileden gelirler. Eğitilme biçimleri olarak aynı anda iki sinir ağını da birbirlerine rakip olarak eğitiyorlar. Her ikiside birbirinden daha iyi performans göstermeye çalışan bir jeneratör ve bir ayırıcı.
Jeneratör, gizli dağılımlardan rastgele belirlediği girdileri sindirerek veri noktalarını oluşturur ve bu veri noktalarını başka bir şekle dönüştürür.
Ayırıcı ise girdinin nereden geldiğini tahmin edebilmek için orijinal verilerden gelen ve jeneratörden gelen girdileri sindirir. Jeneratörün ayırıcının karar verme sürecine erişimi olabilmesinin tek gerekçesi her iki ağında eğitimde birbirlerine bağlı olmasıdır. Her iki ağ birlikte eğitildiğinde, ayırıcıya gelen verilerdeki kalıplardan gerçekçi görünüp görünmediklerini öğrenmesi gerekirken, jeneratörün rastgele gelen girdilerinden daha gerçekçi örnekler oluşturarak ayırıcıyı alt etmeyi öğrenir
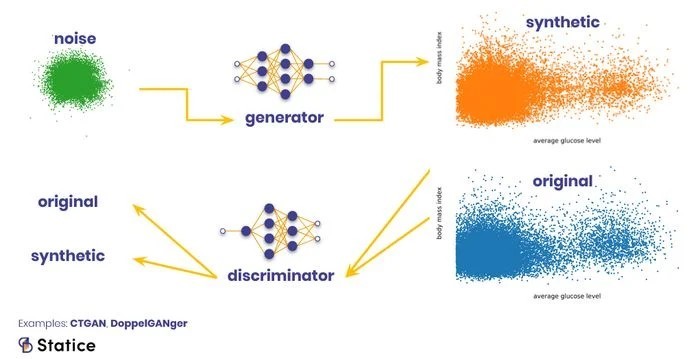
GAN’ların bu yöntemdeki avantajı yeniden yapılandırma hatası vermenize gerek kalmamasıdır. Ayırıcı “orijinal” verilerin özelliklerini öğrenir. Genel olarak GAN’lar yapılandırılmamış verilerde VAE’lere göre daha iyilerdir. Bununla birlikte maalesef GAN’ların eğitebilmesi VAE’lerin eğitilmesinden daha zordur.
Sentetik Veri Oluştururken Nelere Dikkat Etmeliyiz?
Her modelin iyi yanları ve kötü yanları bulunmaktadır. Birden çok veri türüyle uyumlu bir şekilde çalışan ve bağımsız bir şekilde veri üreten bir model bulmak zordur. Çoğu zaman kurumsal bağlamda böyle bir modele ihtiyaç duyacaksınız. Fakat genellikle bulmanız çok zor olacak böyle durumlarda uygun yaklaşımları seçmek için hangi bilgilerle çalışmanın size yeterli olacağını ve hangi bilgilerin işinize yarayacağını iyi analiz etmeniz işiniz kolaylaştıracaktır.
Bir diğer sorun, gizliliği korumak istediğiniz zamanlarda, orijinal veri kümesinin boyutundan kaynaklanır. Bir veri kümesinde ne kadar çok veri ve giriş varsa, istatistiksel özelliklerinin o kadar iyi yansıtır. Bunun zıttı olan seyrek veri kümelerinde gizliliğe saygı duyan veri tipleri oluşturmak daha zordur.
Son olarak, Sentetik Verilerin kendi başlarına zayıf veri kalitesi ve önyargılı veriler için mucizevi bir çözüm olmadığını belirtmek isterim. Sentetik verilerin kalitesi modelin kalitesi ile doğru orantılıdır. Modelin kalitesi ise orijinal verinin kalitesine göre değişir.



